We present Imagen Video, a text-conditional video generation system based on a cascade of video diffusion models. Given a text prompt, Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models. We describe how we scale up the system as a high definition text-to-video model including design decisions such as the choice of fully-convolutional temporal and spatial super-resolution models at certain resolutions, and the choice of the v-parameterization of diffusion models. In addition, we confirm and transfer findings from previous work on diffusion-based image generation to the video generation setting. Finally, we apply progressive distillation to our video models with classifier-free guidance for fast, high quality sampling. We find Imagen Video not only capable of generating videos of high fidelity, but also having a high degree of controllability and world knowledge, including the ability to generate diverse videos and text animations in various artistic styles and with 3D object understanding.
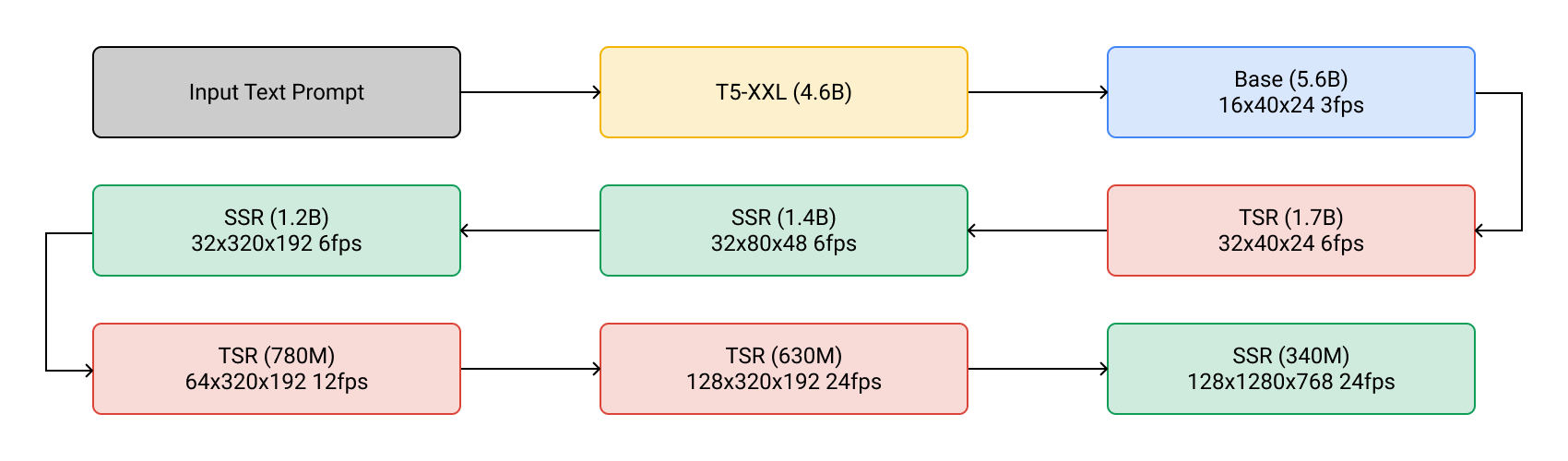
Imagen Video generates high resolution videos with Cascaded Diffusion Models. The first step is to take an input text prompt and encode it into textual embeddings with a T5 text encoder. A base Video Diffusion Model then generates a 16 frame video at 40×24 resolution and 3 frames per second; this is then followed by multiple Temporal Super-Resolution (TSR) and Spatial Super-Resolution (SSR) models to upsample and generate a final 128 frame video at 1280×768 resolution and 24 frames per second -- resulting in 5.3s of high definition video!
Sprouts in the shape of text 'Imagen' coming out of a fairytale book.
Text Prompt
→
Base 16×40×24 3fps
→
TSR 32×40×24 6fps
→
SSR 32×80×48 6fps
→
SSR 32×320×192 6fps
→
TSR 64×320×192 12fps
→
TSR 128×320×192 24fps
→
SSR 128×1280×768 24fps
Imagen Video generates high resolution videos with Cascaded Diffusion Models. The first step is to take an input text prompt and encode it into textual embeddings with a T5 text encoder. A base Video Diffusion Model then generates a 16 frame video at 40×24 resolution and 3 frames per second; this is then followed by multiple Temporal Super-Resolution (TSR) and Spatial Super-Resolution (SSR) models to upsample and generate a final 128 frame video at 1280×768 resolution and 24 frames per second -- resulting in 5.3s of high definition video!
Video U-Net
Spatial Fidelity × Temporal Dynamics
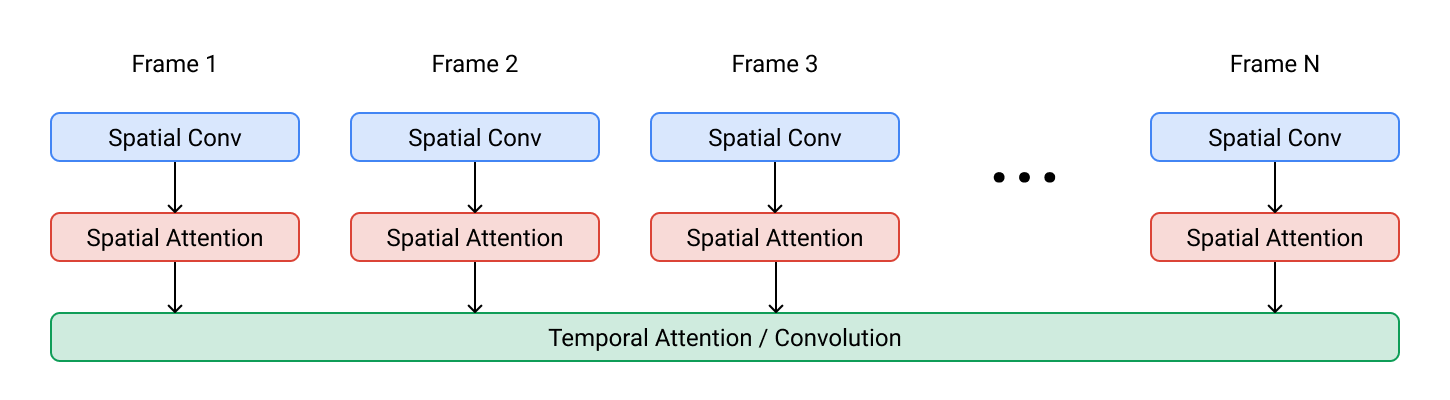
Imagen Video uses the Video U-Net architecture to capture spatial fidelity and temporal dynamics. Temporal self-attention (shown in the diagram) is used in the base video diffusion model, while temporal convolutions (not shown in the diagram) are used in the temporal and spatial super-resolution models. The Video U-Net architecture empowers Imagen Video to model long-term temporal dynamics!
Video
U-Net
Spatial Fidelity × Temporal Dynamics
Spatial Convolutions
↓
Spatial Self-Attention
↓
Temporal Attention
Spatial Convolutions
↓
Spatial Self-Attention
↓
Temporal Attention
Spatial Convolutions
↓
Spatial Self-Attention
↓
Temporal Attention
Spatial Convolutions
Spatial Self-Attention
Temporal Self-Attention
Imagen Video uses the Video U-Net architecture to capture spatial fidelity and temporal dynamics. Temporal self-attention (shown in the diagram) is used in the base video diffusion model, while temporal convolutions (not shown in the diagram) are used in the temporal and spatial super-resolution models. The Video U-Net architecture empowers Imagen Video to model long-term temporal dynamics!
Limitations
Generative modeling has made tremendous progress, especially in recent text-to-image models. Imagen Video is another step forward in generative modelling capabilities, advancing text-to-video AI systems. Video generative models can be used to positively impact society, for example by amplifying and augmenting human creativity. However, these generative models may also be misused, for example to generate fake, hateful, explicit or harmful content. We have taken multiple steps to minimize these concerns, for example in internal trials, we apply input text prompt filtering, and output video content filtering. However, there are several important safety and ethical challenges remaining. Imagen Video and its frozen T5-XXL text encoder were trained on problematic data. While our internal testing suggest much of explicit and violent content can be filtered out, there still exists social biases and stereotypes which are challenging to detect and filter. We have decided not to release the Imagen Video model or its source code until these concerns are mitigated.
Imagen Video
imagine · illustrate · inspire
Authors
Jonathan Ho*, William Chan*, Chitwan Saharia*, Jay Whang*, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David Fleet, Tim Salimans*
*Equal Contribution.
Special Thanks
We give special thanks to Jordi Pont-Tuset and Shai Noy for engineering support. We also give thanks to our artist friends, Alexander Chen, Irina Blok, Ian Muldoon, Daniel Smith, and Pedro Vergani for helping us test Imagen Video and lending us their amazing creativity. We are extremely grateful for the support from Erica Moreira for compute resources. Finally, we give thanks to Elizabeth Adkison, James Bradbury, Nicole Brichtova, Tom Duerig, Douglas Eck, Dumitru Erhan, Zoubin Ghahramani, Kamyar Ghasemipour, Victor Gomes, Blake Hechtman, Jonathan Heek, Yash Katariya, Sarah Laszlo, Sara Mahdavi, Anusha Ramesh, Tom Small, and Tris Warkentin for their support.